
Feng Pan and Pan Zhang uploaded a new paper on the arXive “Simulating the Sycamore supremacy circuits.” with an amazing announcement.
Abstract: We propose a general tensor network method for simulating quantum circuits. The method is massively more efficient in computing a large number of correlated bitstring amplitudes and probabilities than existing methods. As an application, we study the sampling problem of Google’s Sycamore circuits, which are believed to be beyond the reach of classical supercomputers and have been used to demonstrate quantum supremacy. Using our method, employing a small computational cluster containing 60 graphical processing units (GPUs), we have generated one million correlated bitstrings with some entries fixed, from the Sycamore circuit with 53 qubits and 20 cycles, with linear cross-entropy benchmark (XEB) fidelity equals 0.739, which is much higher than those in Google’s quantum supremacy experiments.
Congratulations to Feng Pan and Pan Zhang for this remarkable breakthrough!
Of course, we can expect that in the weeks and months to come, the community will learn, carefully check, and digest this surprising result and will ponder about its meaning and interpretation. Stay tuned!
Here is a technical matter I am puzzled about: the paper claims the ability to compute precisely the amplitudes for a large number of bitstrings. (Apparently computing the amplitudes is even more difficult computational task than sampling.) But then, it is not clear to me where the upper bound of 0.739 comes from? If you have the precise amplitudes it seems that you can sample with close to perfect fidelity. (And, if you wish, you can get a F_XEB score larger than 1.)
Update: This is explained just before the discussion part of the paper. The crucial thing is that the probabilities for the 2^21 strings are distributed close to Porter-Thomas (exponentials). If you take samples for them indeed you can get samples with F_XEB between -1 and 15. Picking the highest 10^6 strings from 2^21 get you 0.739 (so this value has no special meaning.) Probably by using Metropolis sampling you can get (smaller, unless you enlarge 2^21 to 2^25, say) samples with F_XEB close to 1 and size-biased distribution (the distribution of probabilities of sampled strings) that fits the theoretical size biased distribution. And you can also use metropolis sampling to get a sample of size 10^6 with the correct distribution of probabilities for somewhat smaller fidelity.
The paper mentions several earlier papers in this direction, including an earlier result by Johnnie Gray and Stefanos Kourtis in the paper Hyper-optimized tensor network contraction and another earlier result in the paper Classical Simulation of Quantum Supremacy Circuits by a group of researchers Cupjin Huang, Fang Zhang, Michael Newman, Junjie Cai, Xun Gao, Zhengxiong Tian, Junyin Wu, Haihong Xu, Huanjun Yu, Bo Yuan, Mario Szegedy, Yaoyun Shi, and Jianxin Chen, from Alibaba co. Congratulations to them as well.
I am thankful to colleagues who told me about this paper.
Some links:
Scientists Say They Used Classical Approach to outperform Google’s Sycamore QC (“The Quantum” Written by Matt Swayne with interesting quotes from the paper. )
Another axe swung at the Sycamore (Shtetl-Optimized; with interesting preliminary thoughts by Scott; )


 .
.
 in K[G], so that both
in K[G], so that both  have support of size 21.
have support of size 21.










 Consequently, the two-colour van der Waerden number w(3,k) is bounded below by
Consequently, the two-colour van der Waerden number w(3,k) is bounded below by  , where
, where  . Previously it had been speculated, supported by data, that
. Previously it had been speculated, supported by data, that  .
.
 is the smallest N such that however [N] = {1, . . . , N} is coloured blue and red, there is either a blue m-term arithmetic progression or a red k-term arithmetic progression. The celebrated theorem of van der Waerden implies that
is the smallest N such that however [N] = {1, . . . , N} is coloured blue and red, there is either a blue m-term arithmetic progression or a red k-term arithmetic progression. The celebrated theorem of van der Waerden implies that  is finite.
is finite. . Finding the behaviors of
. Finding the behaviors of  and of
and of  . Similarly, understanding the values of
. Similarly, understanding the values of  , and especially of
, and especially of  and
and  are also central problems in Ramsey theory. A big difference between van der Waerden number and Ramsey numbers is that there are density theorems for the existence of
are also central problems in Ramsey theory. A big difference between van der Waerden number and Ramsey numbers is that there are density theorems for the existence of  -terms arithmetic progressions. (Roth’s theorem for
-terms arithmetic progressions. (Roth’s theorem for  and Szemeredi’s theorem for general
and Szemeredi’s theorem for general  . The best known upper bound is of Tomasz Schoen,
. The best known upper bound is of Tomasz Schoen,  for some constant
for some constant  The best known lower bound until the new paper, was by Li and Shu:
The best known lower bound until the new paper, was by Li and Shu:  . (This result, as the earlier bound by Robertson, used a probabilistic argument and relied on Lovasz’s local lemma.)
. (This result, as the earlier bound by Robertson, used a probabilistic argument and relied on Lovasz’s local lemma.) but now Green proved a super-polynomial lower bound! This is amazing! Congratulations, Ben!
but now Green proved a super-polynomial lower bound! This is amazing! Congratulations, Ben! . (Schoen’s upper bound on
. (Schoen’s upper bound on 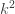 is Ben Green himself. This is recorded in reference [9] of the paper. However, Green’s first reaction to this possibility was that it must be false. But he realized that some ideas for showing that it is false are themselves false.
is Ben Green himself. This is recorded in reference [9] of the paper. However, Green’s first reaction to this possibility was that it must be false. But he realized that some ideas for showing that it is false are themselves false. th scale the example’s cardinality is
th scale the example’s cardinality is  . (So all the empirical data comes from the
. (So all the empirical data comes from the  regime.) Ben Green boldly suggests that the true values of
regime.) Ben Green boldly suggests that the true values of  is quasi-polynomial, namely it lies somewhere in between the bound given by his construction and something like
is quasi-polynomial, namely it lies somewhere in between the bound given by his construction and something like  (which is Behrend-bound behaviour on the nose) .
(which is Behrend-bound behaviour on the nose) .
 are any two real numbers, and
are any two real numbers, and  , then there exists a positive integer
, then there exists a positive integer  such that
such that  . Famously, Einsiedler, Katok and Lindenstrauss proved that the Hausdorff dimension of the set of counterexamples to the conjecture is zero. Gowers had ideas for an elementary approach, and his ideas
. Famously, Einsiedler, Katok and Lindenstrauss proved that the Hausdorff dimension of the set of counterexamples to the conjecture is zero. Gowers had ideas for an elementary approach, and his ideas  and every positive integer
and every positive integer  is any subset of
is any subset of ![[k]^{[n]^2}](https://web.archive.org/web/20210313091858im_/https://s0.wp.com/latex.php?latex=%5Bk%5D%5E%7B%5Bn%5D%5E2%7D&bg=ffffff&fg=333333&s=0&c=20201002 "[k]^{[n]^2}") of density at least
of density at least  , then
, then  for some subset
for some subset ![X\subset[n]](https://web.archive.org/web/20210313091858im_/https://s0.wp.com/latex.php?latex=X%5Csubset%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002 "X\subset[n]") .
.![[k]^n](https://web.archive.org/web/20210313091858im_/https://s0.wp.com/latex.php?latex=%5Bk%5D%5En&bg=ffffff&fg=333333&s=0&c=20201002) force exponentially small density” and “what kind of forbidden patters in
force exponentially small density” and “what kind of forbidden patters in  be a graph. Erdös and Hajnal conjectured that there is a constant
be a graph. Erdös and Hajnal conjectured that there is a constant ") such that if
such that if  is any graph with at least
is any graph with at least  vertices that does not contain any induced copy of
vertices that does not contain any induced copy of  contain a clique of size
contain a clique of size 